

SUBSCRIBE TO OUR NEWSLETTER
Stay informed! Sign up to get expert advice and insight delivered direct to your inbox
Part two of this series looks at the shift to a new data center architecture and the role of networking technologies such as InfiniBand and RoCE.
July 22, 2015

As I explained in part one of this three-part blog series, there has been a dramatic shift in the way in which data needs to be moved and processed, which will require data centers to be re-architected. In this post, I'll examine the evolution in more detail.
The traditional data center was built on a three-tier model comprised of application, database and storage tiers designed to process relatively small, self-contained chunks of data with regular, fixed formats. These architectures were developed to automate online transaction processing of bank deposits, credit card purchases, and ticket reservations. Most of the traffic was north-south from the client through the three tiers, eventually resulting in a transactional commitment to the database and backing networked storage. This led to incredible gains in convenience, accuracy and corporate productivity, but this data model now seems quaint in comparison to the amount and nature of data being produced today.
Figure 1: 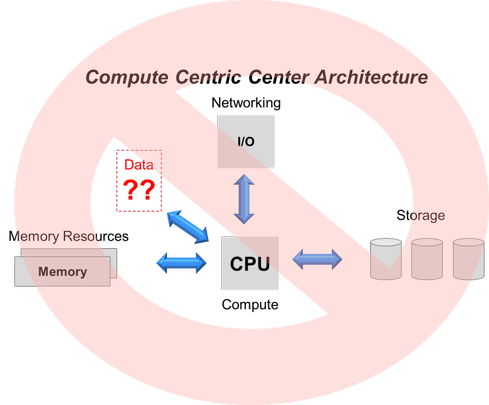
Unfortunately, the compute-centric, three-tier data center architecture that emerged to deal with transactional processing is woefully inadequate to cope with the vast amounts of data generated and processed today. The architecture puts the CPU at the center of the server with peripheral components like memory, networking, and storage connected to the centralized processor. In this CPU-centric view of the server, the ingest, movement, processing, storage and treatment of data is an afterthought. Data is stuck off to the side somewhere and forced to fit within the hardware constraints imposed by the server.
The data-centric data center
So what is a poor data center architect to do? It's not that compute is no longer important; it's more important than ever. But the system architects building the world’s largest data centers don’t start their thinking with compute capacity. The onslaught of data makes them think about the data first: Where it is, where it needs to move, how to access and store it, and of course also how to process it. But compute is no longer at the center of the design and optimization of the data center -- data -- is.
Fortunately, recent developments in big data, machine learning, NoSQL databases, and scale-out clustered system architectures are putting the data back into the center of the data center. This new focus on data changes the optimal data center architecture in several important ways. These changes demand rack level optimization, allowing the disaggregation of compute, storage, and network resources to move from a server-focused architecture optimized for a traditional compute-centric data center to a data-centric data center.
Figure 2: 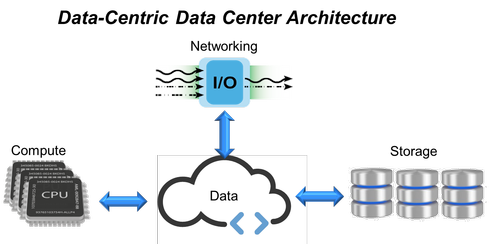
Fundamentally, it's important to recognize that even something as simple as a web search, tweet or ”like” needs to access unbelievable quantities of data. Search and social media indexes are accessing data in excess of 100 petabytes of data. So no single system can contain all this data. As a result, the three-tier architecture ideal for OLTP workloads are being replaced by clustered systems that combine compute, storage and efficient networking into regular compu-storage units that can be scaled out massively to accommodate ever growing data and users.
New networking technologies
This shift from a compute-centric to a data-centric architecture puts tremendous pressure on the networks used to move data between individual nodes. Traditional networking models prove grossly inadequate given the quantity of data, number of nodes participating, and the sophisticated sequence of potentially hundreds of operations required to respond to a single simple user request.
Traditional networking uses relatively slow networks (1 to 10 Gbps) and requires computationally intensive software transport protocol processing simply to deliver data blocks between nodes. Not only does this transport processing consume valuable CPU and memory resources, but it also results in unacceptably long and indeterminate data transfer delays.
Networking technologies such as InfiniBand and RoCE (RDMA over Converged Ethernet) address this issue by implementing direct transfer of data between applications in hardware to deliver ultra-low and deterministic latencies without consuming CPU and memory resources.
Furthermore, with InfiniBand and RoCE, data speeds of 25, 40, 50, and even 100 Gbps are available. So new system architectures become not only possible but critical and with these new technologies, data networking has transitioned from being CPU intensive and requiring tens of microseconds or even milliseconds of latency to sub-microsecond, CPU-less data transfers.
This shift from compute-centric to data-centric data centers requires different types of architectures in order optimize infrastructure, performance, power, and efficiency. And indeed, system architects have responded to these changing requirements with new optimized architectures. The key architectural change is to optimize resources at the rack level rather than at the server level in moving from a compute to a data-centric focus.
There are three key elements required to accomplish rack-level optimization for the data-centric data center:
Disaggregation of server resources
Efficient data movement
High-speed data connectivity
I’ll talk about each of these three requirements in my third and final post in this series.
You May Also Like


