A few months back, I had the opportunity to listen to two keynotes by Alex Stamos, who at the time was the CISO of Yahoo. As part of his talks, Stamos -- who is now CSO of Facebook -- reminded the audience of some fundamental realities about scaling security services in these days of software everywhere, virtualization, containers and high-performing data center fabrics.
One of Stamos' main points was that as we deploy faster networks in our data centers, we literally kill our ability to inspect all traffic inline in hardware. To demonstrate this, he used the example of connecting 1,000 servers at 10 Gigabit Ethernet with the objective of inspecting the traffic between the servers for “east-west traffic by the bad guys,” or segmenting to the server level.
Stamos asked the following question: How many firewalls running at 120 Gbps do I need to inspect the traffic from a single 10 GbE switch with a non-blocking fabric of 30 Tbps?
As shown in the picture above, it would take 250 firewalls requiring more than 600,000 Kw of electricity to deliver the required solution (assuming 2.4Kw / appliance), not to mention all the acquisition and support costs. Again, this is only to microsegment 1,000 10 GbE-attached servers.
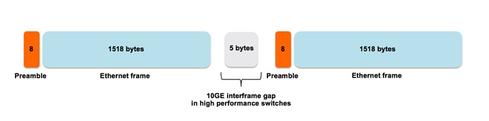
But more importantly, because of the advances in fabrics and line cards, a network running at 10 Gbps leaves 67 nanoseconds between Ethernet frames.
Next-generation security services like application awareness and threat prevention require a lot of work on a packet in order to do their magic and while every security appliance has some buffers to accommodate the bursty nature of IP traffic, nobody builds buffers to compensate processing latency on a constant 10 Gbps stream of traffic. Instead, manufacturers publish lower performance numbers as services are turned on, often dropping by half or more of the original specification.
Sixty-seven nanoseconds then becomes the amount of time a security device has on a 10 GbE network to open a packet, after possibly having to reassemble it, look at the header and pertinent data, compare it to the appropriate security logic and decide if it drops it or let it go through.
When in the not so distant future we will move to 100 Gbps, this will leave a little more than 6 ns between packets. No matter how good we are at designing hardware, we are losing this battle.
Why should we be concerned about these simple facts? Because they prevent our ability to granularly segment and fix the diameter of our perimeters. Or in other words, because we can no longer look at all the traffic with inline centralized hardware products, we have to concede to the attacker a large attack surface as his personal playground.
Stamos concluded: “You can’t take all the security services, centralize them into a single box, and make it cost effective to utilize at web scale -- it’s just impossible. What you have to do is to take each of these firewalls, split them into software components and smear them across hundreds of thousands of servers.”
Crafting a “split and smear” approach
Before diving into the elements of a solution, it is worth spending a minute to understand why centralizing services such as security in the core of the network was considered the best approach to a solid data center design until recently.
We have to look at operational constraints to make sense of it: The small team looking after the data center did not want to manually manage hundreds of routers and thousands of firewalls, load balancers, NAT devices, and proxies, so we ended up deploying fewer, larger, centrally located devices.
The solution to distributing a service such as firewalling needs to address the challenges of managing thousands of distributed instances. Indeed, unless we can provide an operational framework that presents the equivalent of one big firewall for the entire DC while in fact thousands are present, we will not be able to remove the hardware firewalls from the core of the data center and our split-and-smear strategy will fail, leaving us with large unprotected perimeters.
While we all understand the value of distributing the function to achieve scale, i.e., your capacity increases each time you add more compute/ hypervisors in the data center, there is a side benefit to pushing the service to the edge that we often underestimate: we eliminate the network speed from the equation!
Indeed, if you are capable of putting a firewall instance in front of every VM, that instance only needs to run as fast as the VM does and nothing more. Your VM sends 1 Gbps of traffic -- that’s all that firewall needs to handle. Another sends 5 Gbps of traffic; again, that is what the firewall needs to deliver.
Now you can deploy the appropriate security function to the appropriate virtual server independent of the fact that your core data center network is running on a 10 GbE, 40 GbE or even a 100 GbE infrastructure. The VM speed becomes your performance objective.
This micro-segmentation approach also inherently provides segmentation at the VM level, meaning the attack surface open to the hacker is a single virtual server. Now you are able to inspect, as Stamos desired, all the traffic originating or delivered to a VM.
Bruno Germain is a staff systems engineer in the network and security business unit at VMware. He has been designing, implementing or securing networking infrastructures for the last 29 years. As part of the team working on the MiM / SPB standards, he shares patents for his work on the integration of virtual routers to this technology.