As higher-level programming language and development environments have matured, programmers have been given the ability to build more powerful applications with less effort than ever before. No longer needing to worry about the idiosyncrasies of wire network protocols or memory management has allowed developers to focus on building value higher up in the stack, without worrying about more common infrastructure challenges. This has, in part, led to the incredible variety of applications we are surrounded by today.
However, this doesn't come without a cost. These days, many developers are blissfully unaware of just how much complexity actually goes on behind the scenes to make their applications possible. Oftentimes, this means that the developers themselves don't have the knowledge to really track down when something is not working right. IT professionals can offer a huge amount of value to application developers by providing more insight into what's going on behind the scenes.
"That can't possibly happen"
Every developer or administrator has uttered these words at some time or another. It's a perfectly understandable reaction to a confusing situation. But one must always remember that computers do exactly what you tell them to do. The tricky part is, the "you" is a huge set of people because your actual code is leveraging all sorts of tools, libraries and systems, which many others wrote. So the first step is, assume the system is doing precisely what it's being told -- it's just being told something completely wrong.
Real-world example: Character sets
One of the more frustrating problems in network applications are character set issues. First, a little background: As more of the rest of the world comes online, the need to communicate in text with characters that are not part of the Roman alphabet is more important than ever.
This is generally accomplished by communicating using a characters set called Unicode, which is most commonly represented in the UTF-8 format. It even allows for new characters to be added without requiring the display software to be changed (and while it won't be able to display the new character, the content it understands will still be fine). The way the whole emoji library continues to grow is enabled through Unicode generally, and most of the time behind the scenes emojis are represented as UTF-8 characters.
The reason this is challenging is because while Unicode makes it possible to represent virtually every character, not everybody uses Unicode. For example, in Japan the ISO-8859-JP character set is very common, because it contains a far smaller set of characters than Unicode, and thus requires less complex software. Furthermore, the even more challenging part is that a character in one set may look entirely differently on the network wire in another set, even though when displayed it looks exactly the same.
Consider a situation where your company has an application (either in-house developed or from a third party) that runs on your network infrastructure. Everything looks fine across the board according to your metrics, but you get an escalation from either the support team or the application developers that they're getting some weird character set validation errors on certain submissions to this application from your customers. The customer swears up and down that they're submitting their data in UTF-8, so somehow the problem must be in either the application or the network infrastructure.
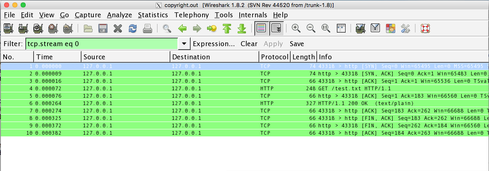
To help diagnose this problem, the easiest thing to do is use your favorite packet sniffer (I use WireShark) to grab the appropriate network traffic. Character set issues almost always involve 8-bit characters, as the vast majority of characters will be 7 bit, at least in the English-speaking world.
For example, consider the registered symbol, which looks like this: ®. In all character sets, that symbol looks the same to the user. However, on the network it looks very different. In UTF-8, it looks like this (in hex digits)
C2 AE
However, in ISO-8859-1 -- another common character set that's technically the first part of the Latin alphabet, and also served as the default character set in HTML4 -- the registered symbol looks like this:
AE
While the second byte is the same, the first one is not. The first byte is the UTF-8 marker that tells it how long the rest of the character is. If somebody thinks data is one character set, but in reality it is another, bad things can happen.
So, if you capture the session to look for invalid UTF8 characters like so:
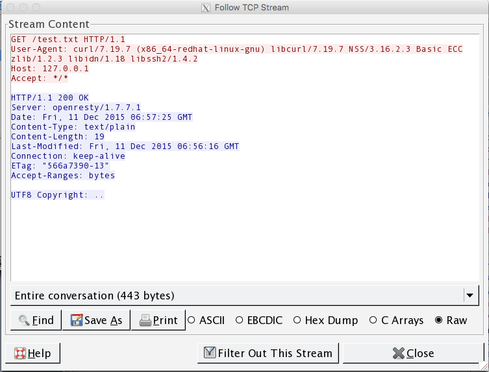
And then right-click on the request you want to view and select "Follow TCP Stream," you'll see a new window showing the entire session:
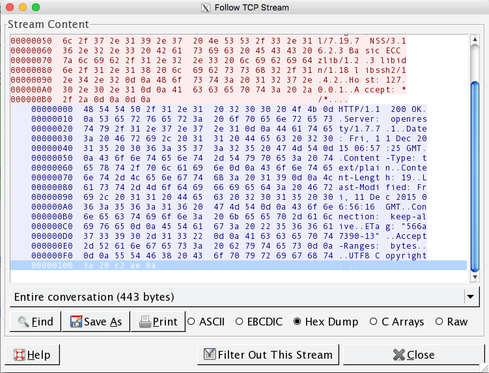
You will see those two period characters after the "UTF8 Copyright" text. Those are non-ASCII characters, which are the ones you want to look for, as for all non-ASCII UTF8 characters they will show up in a dump as periods. To see what they are, switch to "Hex Dump" mode:
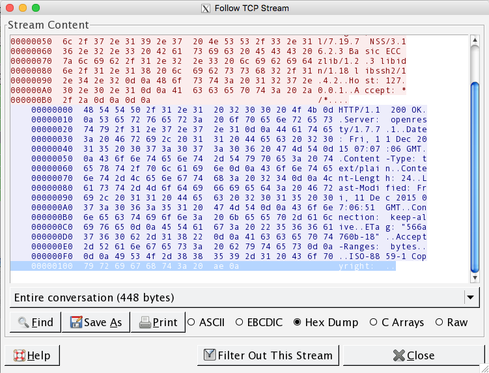
That shows that the UTF8 symbol is in fact represented as C2 AE, which means it's UTF8. However, if we changed it to be the ISO-8859-1 representation, it would look like this:
Note that now it only shows up as AE, as opposed to C2 AE. Most modern text editors will show the content exactly as this in both cases, but it requires a network dump to tell the difference:
ISO-8859-1 Copyright: ®
Of course this is just one example of the kinds of diagnostics that an IT person can do as part of helping to diagnose higher-level application problems. With the advent of more complex application server platforms, developers become more and more disconnected from the underlying network. By helping developers and business owners track down problems such as these, the whole organization benefits.
As the chief technology officer of SparkPost, Alec Peterson is leading development, setting the engineering agenda and ensuring that at every step, the product and underlying technology is nothing short of cutting edge. Alec leverages more than 15 years of network engineering, cloud, and design experience to advance the SparkPost technology vision. Under his guidance, the company develops email solutions including SparkPost, SparkPost Elite and Momentum – the platform on which SparkPost cloud services are based. At SparkPost, Alec has responsibility over engineering, technical operations and IT, and plays a critical role in understanding the evolving needs of an ever-growing client base including global brands like Pinterest, Zillow, Twitter and LinkedIn.