These are best practices and proven practices for how a design for all components in the SDDC might look. It will highlight a possible cluster layout, including a detailed description of what needs to be put where, and why a certain configuration needs to be made.
Typically, every design should have an overview to quickly understand what the solution is going to look like and how the major components are related. In the SDDC one could start drawing the vSphere Clusters, including their functions.
Logical overview of the SDDC clusters
This following image describes an SDDC that is going to be run on the three-cluster approach:
The three clusters are as follows:
- The management cluster for all SDDC managing services
- The NSX edge cluster where all the north-south network traffic is flowing through
- The actual payload cluster where the production VMs get deployed
Tip: Newer best practices from VMware, as described in the VMware validated designs (VVD) version 3.0, also propose a two-cluster approach. In this case, the edge cluster is not needed anymore and all edge VMs are deployed directly onto the payload cluster. This can be a better choice from a cost and scalability perspective. However, it is important to choose the model according to the requirements and constraints found in the design.
The overview should be only as complex as necessary since its purpose is to give a quick impression over the solution and its configuration. Typically, there are a few of these overviews for each section.
This forms a basic SDDC design where the edge and the management cluster are separated. According to the latest VMware best practices, payload and edge VMs can also run on the same cluster. This basically is a decision based on scale and size of the entire environment. Often it is also a decision based on a limit or a requirement -- for example, edge hosts need to be physically separated from management hosts.
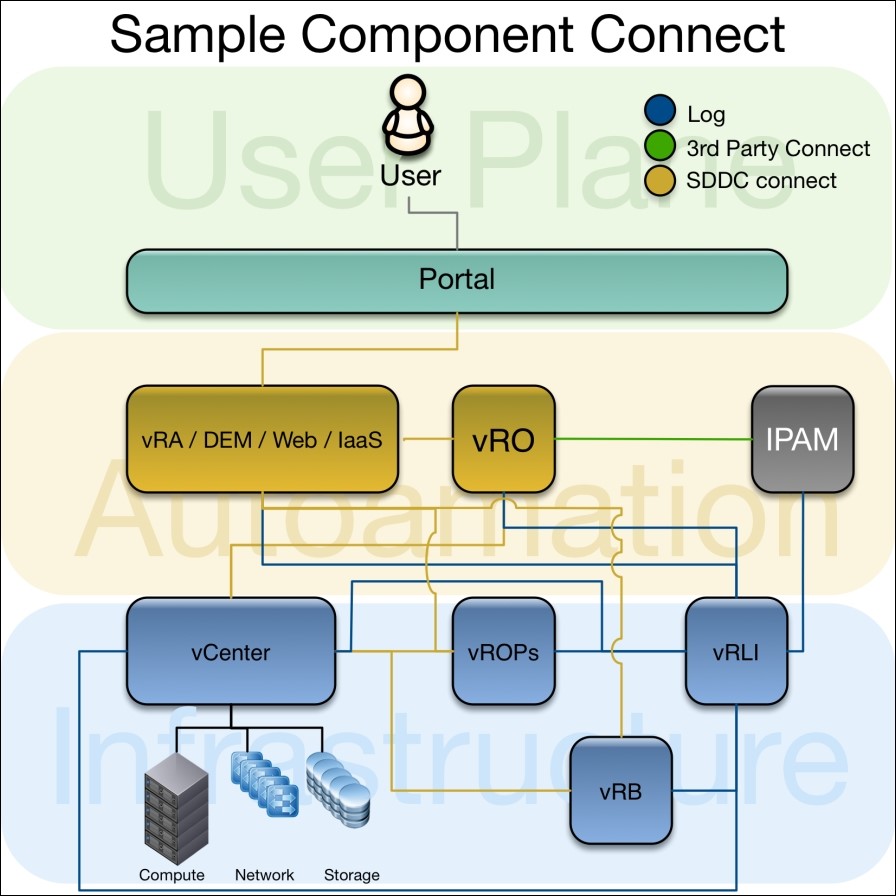
Logical overview of solution components
This is as important as the cluster overview and should describe the basic structure of the SDDC components, including some possible connections to third-party integration like IPAM.
Also, it should provide a basic understanding for the relationship between the different solutions.
It is important to have an understanding of these components and how they work together. This will become important during the deployment of the SDDC since none of these components should be left out or configured wrong. For the vRealize Log Insight connects, that is especially important.
Note: If not all components are configured to send their logs into vRealize Log Insight, there will be gaps, which can make troubleshooting very difficult or even impossible. A plan, which describes the relation, can be very helpful during this step of the SDDC configuration.
These connections should also be reflected in a table to show the relationship and confirm that everything has been set up correctly. The better the detail is in the design, the lower the chance that something gets configured wrong or is forgotten during the installation.
The vRealize Automation design
Based on the use case, there are two setup methods/designs vRealize Automation 7 supports when being installed.
Small: Small stands for a very dense and easy-to-deploy design. It is not recommended for any enterprise workloads or even for production. But it is ideal for a proof of concept (PoC) environment, or for a small dev/test environment to play around with SDDC principles and functions.
The key to the small deployment is that all the IaaS components can reside on one single Windows VM. Optionally, there can be additional DEMs attached which eases future scale. However, this setup has one fundamental disadvantage: There is no built-in resilience or HA for the portal or DEM layer. This means that every glitch in one of these components will always affect the entire SDDC.
Enterprise: Although this is a more complex way to install vRealize Automation, this option will be ready for production use cases and is meant to serve big environments. All the components in this design will be distributed across multiple VMs to enable resiliency and high availability.
In this design, the vRealize Automation OVA (vApp) is running twice. To enable true resilience a load balancer needs to be configured. The users access the load balancer and get forwarded to one of the portals. VMware has good documentation on configuring NSX as a load balancer for this purpose, as well as the F5 load balancer. Basically, any load balancer can be used, as long as it supports HTML protocol checks.
Note: DNS alias or MS load-balancing should not be used for this, since these methods cannot prove if the target server is still alive. According to VMware, there are checks required for the load balancer to understand if each of the vRA Apps is still available. If these checks are not implemented, the user will get an error while trying to access the broken vRA
In addition to the vRealize Automation portal, there has to be a load balancer for the web server components. Also, these components will be installed on a separate Windows VM. The load balancer for these components has the same requirements as the one for the vRealize Automation instances.
The active web server must only contain one web component of vRA, while the second (passive) web server can contain component 2, 3, and more.
Finally, the DEM workers have to be doubled and put behind a load balancer to ensure that the whole solution is resilient and can survive an outage of any one of the components.
Tip: If this design is used, the VMs for the different solutions need to run on different ESXi hosts in order to guarantee full resiliency and high availability. Therefore, VM affinity must be used to ensure that the DEMs, web servers or vRA appliances never run on the same ESXi host. It is very important to set this rule, otherwise, a single ESXi outage might affect the entire SDDC.
This is one of VMware's suggested reference designs in order to ensure vRA availability for users requesting services. Although it is only a suggestion it is highly recommended for a production environment. Despite all the complexity, it offers the highest grade of availability and ensures that the SDDC can stay operative even if the management stack might have troubles.
Tip: vSphere HA cannot deliver this grade of availability since the VM would power off and on again. This can be harmful in an SDDC environment. Also, to bring back up operations, the startup order is important. Since HA can't really take care of that, it might power the VM back on at a surviving host, but the SDDC might still be unusable due to connection errors (wrong order, stalled communication, and so on).
Once the decision is made for one of these designs, it should be documented as well in the setup section. Also, take care that none of the limits, assumptions, or requirements are violated with that decision.
Another mechanism of resiliency is to ensure that the required vRA SQL database is configured as an SQL cluster. This would ensure that no single point of failure could affect this component. Typically, big organizations have already some form of SQL cluster running, where the vRA database could be installed. If this isn't a possibility, it is strongly recommended to set up such a cluster in order to protect the database as well. This fact should be documented in the design as a requirement when it comes to the vRA installation.
This tutorial is a chapter excerpt from "Building VMware Software-Defined Data Centers" by Valentin Hamburger. Use the code ORSCP50 at checkout to save 50% on the recommended retail price until Dec. 15.