Getting stranded in an airport due to a cancelled flight is about as pleasurable as going to the dentist to get your teeth drilled. Unfortunately, travel disruptions due to IT system outages have become all too common. Earlier this week, an estimated 280 flights were cancelled and many others delayed due to Delta computer problems. If this sounds familiar, you probably remember when thousands of travelers were stranded after an even bigger Delta systems outage resulted in more than 2,000 flight cancellations over a three-day period in 2016.
These computer failures are a prime example of what happens when mission-critical IT infrastructure fails and backup systems don’t kick in quickly enough, resulting in big consequences. For Delta, the preventable outages cost it $100 million dollars in lost revenue, lost business, and damage to reputation.
These incidents also draw attention to the patchwork and often outdated nature of IT systems that power many airlines and businesses in other industries, which will no doubt contribute to future failures. While this week’s outage wasn’t as severe as the one Delta experienced last August, it further points to the fact that both outdated IT systems and inadequate disaster recovery planning will lead to more failures if changes aren’t made.
Disaster recovery planning
In light of the recent outages at Delta -- and similar ones at United and Southwest -- how can organizations avoid disruptions to IT services others depend on? While occasional mishaps are unavoidable, a little planning and investment in infrastructure can help companies sidestep, or at least more quickly recover from similar IT challenges.
To prevent avoidable failures, companies should thoroughly evaluate their disaster recovery plans and build redundancy into their systems where possible. Taking time to walk through potential failure scenarios and auditing the effectiveness of existing systems can also help avoid disaster.
For example, in the August 2016 failure, a potentially outdated power control module in Delta’s Atlanta-based data center failed, causing a small fire that was quickly extinguished. The good news? Delta had a backup power system in place. The bad news? Approximately 300 out of 7,000 servers at Delta weren’t wired to backup power, a flaw in the company’s planning that caused the entire Delta computer system to a grind to a halt, Delta CEO Ed Bastian told The Atlanta Journal-Constitution.
A wakeup call
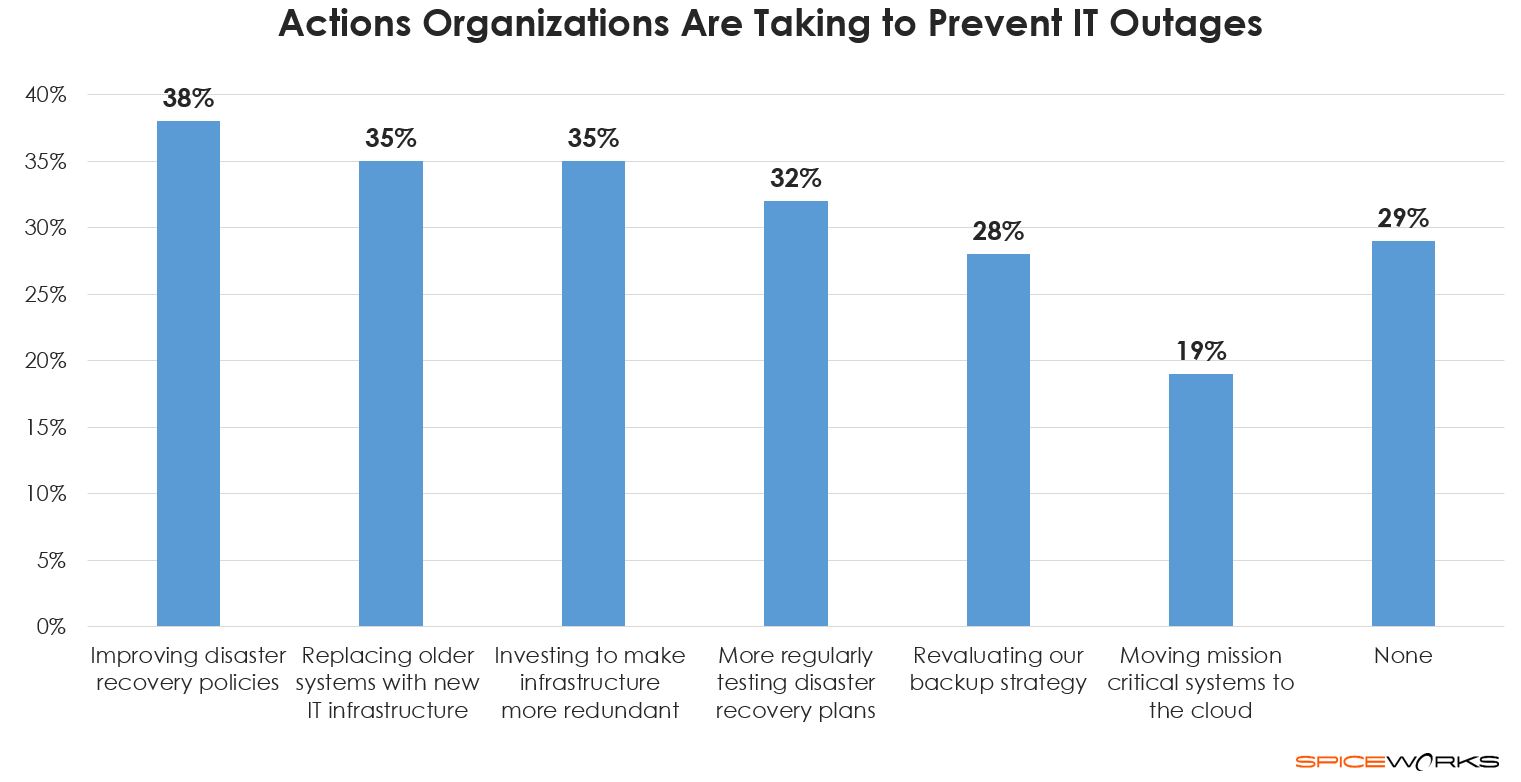
If there’s a silver lining to the recent Delta incidents, it’s that high-profile outages have spurred many companies into action. In fact, a Spiceworks poll revealed that found a majority of organizations are taking steps to prevent IT disasters in light of the recent IT outages at airlines.
As to what they plan to do, respondents said the No. 1 step they plan to take is to improve their disaster recovery policies and procedures. This might include preparing a more comprehensive DR plan that covers likely “what if” scenarios that can bring your IT systems down, such as power outages, hardware failure, human error, and natural disasters.
Many companies also plan to replace their older IT systems with newer infrastructure and to invest in making their IT infrastructure more redundant. This typically involves testing backup and failover systems to make sure they’ll actually work when it counts. By rehearsing disaster recovery scenarios regularly, you also help ensure a faster time to recovery in the event of an incident. If systems are redundant enough, a failure might not result in any downtime at all.
But while many companies are taking steps to prevent IT outages, we also found that nearly 30% of organizations aren’t planning to make any changes at all.
I'm sure you're familiar with Murphy’s law: “Anything that can go wrong, will go wrong.” The same goes for disaster recovery planning. It’s not a matter of if something will happen, it’s a matter of when. To be truly effective, disaster planning needs to be looked at closely as a primary part of IT strategy, not just an afterthought. While the Delta outages are still fresh on the minds of management and IT pros alike, there’s no better time for action than the present.