While it's too early to start thinking of holiday shopping for most of us, retailers across the country have begun investing in projects to ensure that their IT systems do not encounter major hiccups during the peak shopping season. With continuing growth in online and mobile commerce, every minute of IT downtime translates into lost revenue, especially during peak holiday season.
This was painfully made aware to all by some headline-making disruptions at Best Buy and HP on Black Friday in 2014 and even at Starbucks earlier in 2015. IT systems are becoming so critical to business operations that every hour of downtime can cost an organization upwards of $100K per hour, according to IDC. So, when CTOs, CIOs, network admins and IT administrators make plans for ensuring a trouble-free holiday season, they must evaluate the resilience of their IT systems -- the ability to guard against failures, but also to recover efficiently from fault conditions.
"Redundancy" is only half a solution for "availability"
The traditional and predominant approach to dealing with downtime has been to build layers of redundancy into IT system to prevent a single point of failure. At the hardware level, there are abundant protocols and mechanisms for it -- from VRRP for redundant routers, to link aggregation in switching, as well as server clustering, load balancing and more. Most critical enterprise software systems are also designed to run on clusters of servers, such as Microsoft Exchange Clustering and Oracle RAC (Real Application Clusters), along with many other enterprise-grade products.
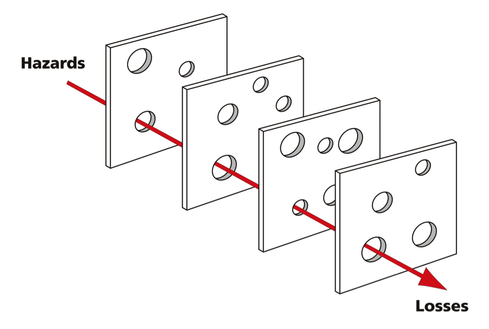
Despite all of that redundancy, disruptions do happen; and some of them are quite severe. Why is adding more redundancy not enough? It is because failures are guaranteed to happen. And if you are a believer in Murphy's Law, failures happen at the worst possible time. Same thing for IT systems. While redundancy builds in a backup mechanism, you also need a way to recover quickly and efficiently from those failures. Every once in a while, a "perfect storm" builds up and brings the system down. In the area of reliability engineering, this is sometimes represented pictorially through the "Swiss cheese model" shown below.
Figure 1:
(Image: davidmack via Wikimedia Commons)
According to Wikipedia, "The Swiss cheese model of accident causation illustrates that, although many layers of defense lie between hazards and accidents, there are flaws in each layer that, if aligned, can allow the accident to occur." The illustration provides a good visual starter for discussing how simple hazards can lead to accidents. For a more comprehensive analysis of hazard detection and preventing accidents -- from IT failures to aviation accidents and nuclear disaster, I strongly recommend the book Engineering a Safer World by Prof. Nancy Leveson at MIT.
From redundancy to resilience
Hopefully, IT professionals reading this article are now convinced that throwing money at additional redundancy will not necessarily increase the availability of their IT systems, and that failures will happen. IT leaders need to look at "availability" in a more comprehensive way and develop a resilience strategy. This guards against failures, but also provides an effective and efficient mechanism for recovery.
Unfortunately, in many IT organizations, the approach to recovery is a little bit of a Wild, Wild West approach, and we deal with it when it happens. Thin IT budgets, over-stretched staff, and backlogged projects do not help either. That is the reason an average IT fault takes an average of 9 hours to fix.
At a broad level, IT organizations need to analyze and understand the failure modes of their systems and have standard operating procedures (SOPs) in place for dealing with failures. This is usually an incremental improvement process that often requires intra-organizational participation and may even entail a cultural mind-shift.
On a more tactical level, one important aspect of resilient IT systems is management of your critical assets, especially at remote sites like branch offices, retail stores, or gas stations. A well-designed management system will not only help reduce incidents of downtime but also help in overall cost reduction of maintaining enterprise IT systems.
IT systems are becoming more and more critical in organizations of all sizes -- from large retail stores to small non-profit organizations, and everything in between. The reliability and security of these systems is critical for each organization at a micro level, and it would not be an exaggeration to say that it is important for the economy at a macro level. We hope CTOs, CIOs, and IT administrators think more seriously about resilience to prevent new disasters from happening.