As big data initiatives become a corporate priority, many companies are questioning whether IT infrastructure choices made for traditional relational databases, data warehouses, and business intelligence deployments are still the optimal approach. Data management platforms, scale and variety of data sets, time sensitivity of analytics, user and consumer engagement, and underlying economics are all quickly changing.
As this happens, both the potential for new business value and the operational requirements to build a workable technology stack also change. So how are customers today evaluating possible solutions, and which big data deployments models will eventually prevail? Research at Enterprise Strategy Group (ESG) has shown a wide range of preferences, but the landscape continues to shift, and many customers remain perplexed.
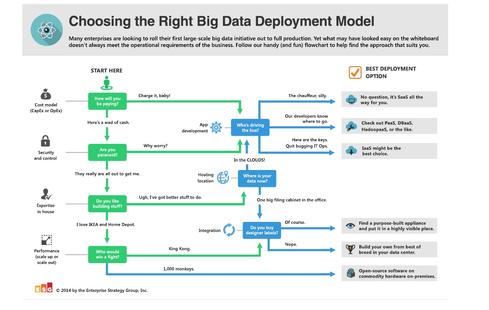
To help, I created this handy (and humorous) quick-reference flow chart to choose the right big data deployment model for your environment.
Does that help? Well, if you’d like to go deeper, you’re in luck as I'm planning a series of blogs to explore some of the factors influencing big data technology strategies. These fundamental choices include:
Commodity versus purpose-built infrastructures. While Hadoop and many scale-out MPP (massively parallel processing) databases promise linear scalability with large numbers of relatively inexpensive commodity servers handling a distributed workload, this is not always aligned to the operational needs of the environment. Some enterprise applications may benefit from more memory, higher performance processors, and/or SSD storage, and not all hardware has the same profile for reliability and ease of administration.
In addition, appliances can offer tight integration for advanced functionality and a “ready-to-go” package for short time-to-value and better supportability. So the question is, will a transition take place and to what extent? Which applications and workloads best fit each style and how might this change over the next several years?
Dedicated vs. shared resources. Many in the industry talk about moving the analytics as close as possible to the data to avoid the delay, complexity, and effort of extract, transform, and load (ETL) activities. However, some are now questioning whether having a one-to-one mapping of server and storage resources makes sense.
Decoupling the inflexibility of embedded storage in servers is seen as desirable by some, but what are the trade-offs in sharing pools of centralized resources? How do data warehouses, lakes, and/or hubs need to evolve to dynamically “right-size” the hardware capabilities to match different analytics and archive use cases?
On-premises vs. public cloud services. Just as cloud computing has impacted the wider world of IT, it will have a definite place in the big data market. Even as IaaS, PaaS, and SaaS all offer tangible benefits and drawbacks, new and more tailored offerings are emerging, including big data-as-a-service, Hadoop-as-a-service, database-as-a-service, and more. When does it make sense to perform analytics in the cloud? What are the security, privacy, and governance considerations? Can hybrid cloud approaches work when the volumes of data spans to petabytes?
Open source vs. proprietary software. Echoing the debate between commodity and purpose-built, there are conflicting camps on how important it is to stay true to open source initiatives like Apache Hadoop, Cassandra, MongoDB, Riak, and others. Is “common core” (sticking close to open source on central items while developing varied approaches to add-on features) as good as true open source for avoiding vendor lock-in? When do unique innovations in proprietary solutions trump the concerns of “getting forked”?
Stay tuned for answers to these questions in future posts. Are you weighing your options for big data deployment? Share your experience, questions, or opinions in the comments section below.