Cloud transitions can be difficult to begin. Transitions can be difficult to design and plan, as much of the diligence now falls on the customer side. This change is a double-edged sword; it cuts both ways. It enables the customer to have significantly more control over designs, technical choices, economics, and risk. It also places the significantly more of the cloud computing architecture burden on the customer, who may not have the level of solution design experience that many service providers do.
Baseline cloud computing architectures are foundational building blocks to cornerstone design ideas. These common design arrangements can be used to jump-start solution efforts. Baseline architectures are useful when leveraging standard cloud computing patterns. Patterns represent cloud service requirements, while baseline architectures provide useful models for handling common architectural components and their associated requirements.
Each of the following sections will build on the section previous. The baseline compute component takes into account a web layer, application layer, and database layer, each having some level of storage. Storage attributes will change based on design requirements. Nearly all modern designs will have web, app, and database layers in their designs.
This type of layering is called tiering. Most designs will have three or four tiers. Tiers are typically the number of individual isolated layers between the environment entry point and the destination data. As an example, a three-tier architecture has a web layer, app layer, and database layer. A single-server architecture will have all three layers residing on the same virtual or physical server.
In this article, we will cover the following topics:
- Baseline architecture types
- OSI model and layer description
- Complex architecture types
- Architecting for hybrid clouds
Baseline architecture types
The various types of baseline architectures are as follows.
Single server
Single server templates represent the use of one server, virtual or physical, that contains a web server, an application, and a database. An example is the LAMP Stack (Linux, Apache, MySQL, PHP). Single server architectures are not very common, as they have inherent security risks as one compromise can compromise all. These architectures are commonly deployed for development work, allowing developers to quickly build functionality without having to deal with connectivity and communication issues between different servers, potentially in different locations.
Single-site
Single-site architectures take the single server architecture and split all of the layers into their own compute instances, creating the three-tier architecture mentioned. With all compute resources located in the same location, single-site architecture is created. There are two versions of single-site architectures: non- redundant and redundant.
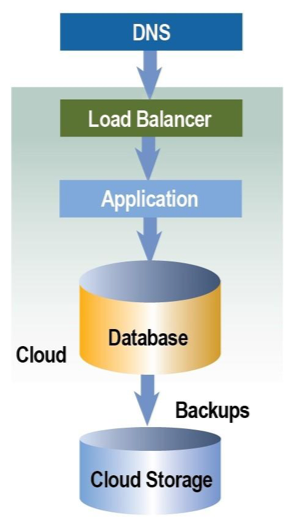
Non-redundant three-tier architectures
Non-redundant three-tier architectures (at right) are used to save on costs and resources but must accept a higher risk. A single failure in any component, a single point of failure, can stop traffic flowing correctly into or out of the environment. This approach is commonly used for development or testing environments only. The following figure shows each layer, or tier, as a separate server, virtual or physical. Using this type of design for production environments is not recommended.
Redundant three-tier architectures
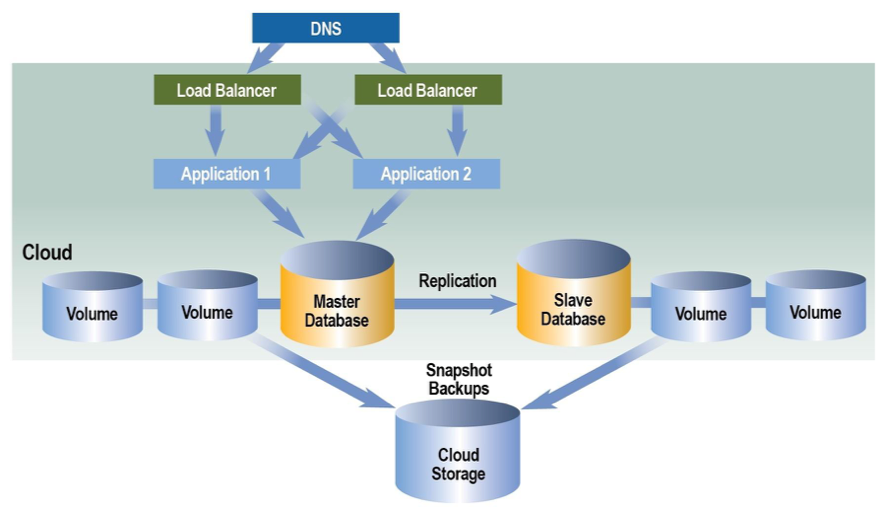
Redundant three-tier architectures add another set of the same components for redundancy. Additional design components do increase complexity, but are required if designing for failover and recovery protection. Designing redundant infrastructures requires a well thought out plan for the components within each layer (horizontal scaling), as well as a plan for how the traffic will flow from one layer to another (vertical scaling).
Single points of failure
In redundant architectures, duplicate components eliminate the single point of failure present when only one device or component is present in the layer. With one component in a layer, there is only one way in and one way out. A second device adds multiple ingress and egress points to the design, eliminating the single point of failure associated with single-component layer designs.
Redundancy versus resiliency
Redundancy and resiliency are often confused. They are related, but not interchangeable. Redundancy is something that is done to prevent failure, implying that it happens before an issue happens. Resiliency, from the word resolve, relates to how to find solutions after a problem has occurred. Redundancy is before the issue. Resiliency is after. For example, redundant databases with replication can be utilized. Multiple components and copies of data create a redundant design. If the primary side of the database pair fails, the secondary side will promote to primary and begin to pick up the load while the failed side self-repairs. The failover and self-healing functions are resiliency. Both are related, but not interchangeable.
Horizontal scaling
Working outside in, the XYZ website has a single web server. A recent outage has suddenly identified available budget money for redundant components at each layer of the current design. By the way, every company is one major outage away from adding budget money for redundancy plans. One web server is currently used in the design. To add redundancy, we must horizontally scale the web server layer by adding additional web servers, eliminating the single point of failure. How will traffic be passed to both servers? How does the packet on the wire know which web server to go to and which path to take in and out, and how is all of this physically connected?
Load balancing is a major design component when adding redundancy to designs. A single load balancer will help delegate traffic across multiple servers, but a single load balancer creates another single point of failure. For redundancy, two or more load balancers are added to designs. Load balancers control traffic patterns. There are many interesting configurations to consider when deciding how to control and distribute traffic. Distribution may relate to traffic type, content, traffic patterns, or the ability of the servers to respond to requests. Load balancers help to handle traffic logically; how is the traffic handled at the physical layer?
OSI model and layer description
The OSI stack is a great tool when working with complex designs. Every layer in the OSI stack must be considered within the design and have a purposeful answer. Designs always start at the physical layer, working up the stack from the bottom to the top. See the following diagram. Many load balancers today work at all layers of the OSI stack. Back to the question: how are multiple load balancers physically connected to multiple servers creating multiple ingress and egress paths? Multiple switches may also be required. Today many load balancers combine the port density of switches, the routing capability of routers, and the logical functions of load balancers, all in a single device simplifying designs and saving a bit of budget money.
The web layer and application layers can often be collapsed into the same server. From a security perspective, this can be an issue. If the server is compromised, both services are potentially compromised. Many designs collapse these two layers, as they are tightly integrated, and performance can significantly increase using system bus speeds instead of slower network connections and additional devices.
From single server designs to single site to single site redundant, each design builds on the one previous. The following figure adds the additional components, servers, and load balancers to illustrate a baseline architecture for single site designs with redundancy. The following redundant design collapses both web and app onto the same virtual or physical server. Load balancers are added to the design to delegate the load across multiple servers. Database servers are shown as primary-backup with replication between them. This redundant architecture can protect against issues with applications due to system unavailability and downtime. Resiliency considerations may include RAID configurations for database drives, how databases are backed up and restored, how applications and devices handle state and session information, and how databases rebuild after data or drive loss.
Logical and physical designs
Designs can be logical or physical. It is very important to remain clear on what is represented. Logical diagrams illustrate how things logically flow through the design. Eliminating some of the physical connections may help the viewer focus on logical flows through the design. Conversely, physical layouts may not include many of the logical details and configurations to focus the viewer on physical characteristics and attributes of the design. The illustrations in this section are logical unless specifically called out as physical.
Autoscaling architecture
A key benefit of cloud computing is the ability to consume what is needed when it is needed. Autoscaling describes the ability to scale horizontally (that is, shrink or grow the number of running server instances) as application user demand changes over time. Autoscaling is often utilized within web/app tiers within the baseline architectures mentioned. In the following figure, an additional server is dynamically added based on demand and threshold settings.
Load balancers must be preconfigured or configured dynamically to handle the new servers that are added.
Keep reading the additional sections of this excerpt:
Complex Cloud Architecture Types
Hybrid Cloud Architecture Concepts
This tutorial is an excerpt from Architecting Cloud Computing Solutions by Kevin L. Jackson and Scott Goessling and published by Packt. Get the recommended ebook for just $10 (limited period offer).