As discussed in the previous chapters, Internet Protocol (IP) is a layer 3 protocol. Recall that a primary function of layer 3 is routing of packets across different subnets. Every interface that is connected to the network needs to have an IP address for identification. Since IP addressing design is critical to any network, we will start with a quick recap of IP addressing and then delve into the considerations for IP address planning for networks.
An IP address is a logical identifier for an interface that is connected to the network. Two versions of IP are currently in use: IPv4 and IPv6. We will focus on IPv4 in this book.
IPv4 addresses
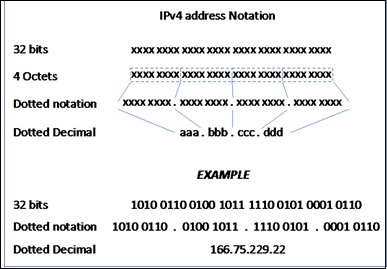
An IP address is a 32-bit identifier that uniquely identifies an endpoint on an IP network. Remembering a 32-bit IP address would be a nightmare, so the address is represented as a dotted decimal notation.
Firstly, the 32 bits are grouped into four octets having 8 bits each. Secondly, the IP address is represented in a doted decimal notation, meaning that the four octets are separated by a decimal between them, which is read as a dot while reading the address. Thirdly, the octets are converted into a decimal number for easier identification, and the IP address takes the form A.B.C.D.
The following figure illustrates the steps in converting the 32 bits of an IP address into the familiar dotted decimal notation:
An IP address is a logical address for the network layer of the host connected to the network. Note that each interface of the host has an IP address, and if a host has two interfaces connected to two different networks, it will have two different IP addresses--one for each interface. The host may also have an address for a logical interface, which is different from a physical interface. As an example, most devices on a network will have a logical interface configured as a loop back interface.This is purely a logical interface with no physical interface mapping. This is done to identify the device on the network through the logical interface, as that interface would never go down as long as any one interface on the device is connected to the network and the TCP/IP stack on the device works normally.
Since an IP address is a logical address, it is easy to build a hierarchy in the addressing schema, which is required for routing the packets from one network to another. All interfaces connected on one network have a common network that is a logical identifier for the network. This network number is embedded in the IP address itself, and can be derived from the IP address using the network mask. Another way of looking at the network number being embedded in the IP address is to look at the IP address as a combination of the network number and host number. The 32 bits of the IP address are divided into two parts: the Network Bits on the left, and the Host Bits on the right:
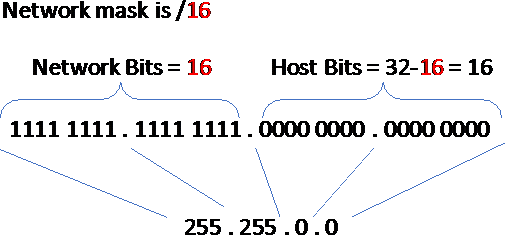
The number of bits that denote the network bits is represented as a value called the network mask. The network mask is denoted as a number between 1 and 32 after a / sign. This is appended to the IP address in the dotted decimal notation. As an example, since the number of network bits in the preceding example is 16, the IP address will be written as 166.75.229.22/16.This means that the IP address is 166.75.229.22 and the network mask is a/16.
Sometimes the network mask is also represented in the dotted decimal notation. To get the dotted decimal notation of the network mask, write the first n bits in the 32 bits as 1, and the remaining trailing bits as 0. Then, convert the resultant 32-bit number into the dotted decimal notation. We use the method shown in the following figure to convert the network mask of/16 into the dotted decimal notation:
If we look only at the network bits and replace all the host bits with a 0, the resultant 32-bit representation is called the network identifier. For the IP address example that we considered earlier, and assuming the network mask is /16, the network identifier is as derived in the following figure:
The network identifier can also be derived by masking the IP address with the network mask in dotted decimal notation. To mask the IP address with the subnet mask, just do a logical AND operation bit by bit for 32bits.Note that a logical AND between a binary1and binary x is x itself, and the result of the AND operation between a binary 0 and a binary x is always 0. Hence, the logical AND operation for the 32 bits will get us the same result, as shown in the following figure:
All hosts on the same layer 3 network have the same network number or ID. Therefore, if a network has a mask of /n, the first n bits of the IP address are the network bits. The remaining (32-n) bits out of the 32 bits of the IPv4 address represent the host part of the address. Since the IP addresses are unique, in a subnet the maximum number of host addresses is 2(32-n). The first and last addresses of the range have a special purpose. The first address will be where all the host bits are 0 and, as we discussed earlier, this number represents the network identifier for the network. If all the host bits of an IP address are set to 1, we get an address that is called the IP broadcast address or broadcast ID for the network, which represents the collection of all hosts/interfaces on the network. Hence, the maximum number of hosts/interfaces on a subnet is 2(32-n)-2. The following figure explains this with the IPv4 example:
When IP addresses were formalized, IP addressing was classified into five classes, A through E, as shown in the following figure. Classes A, B, and C were used for user addressing, while class D was used for multicast addressing, and Class E addresses were reserved for experimental use. The identification of the address was based on the higher order bits in the binary representation of the address. If the highest order bit was 0, the address was a class A address. If the highest order 2 bits were 10, the address was a class B address, and if the highest order 3 bits were 110, it was a class C address. Similarly, the highest order 4 bits for class D and class E addresses were 1110 and 1111 respectively.
The rationale was based on the fact that there would be large, medium, and small networks, and hence three different classes of address, namely A, B, and C, were devised accordingly. The class A addresses were for the largest networks, where the number of hosts would be very large. It was assumed that very few networks of such types would exist on the internet. Accordingly, 8 bits were reserved in a class A address for the network bits in a class A address, and the remaining 32 bits were for hosts. Since the first bit was already set to 0, this meant that there could be 128 such networks (2(8-1)), and each network could have up to 224 - 2 hosts each. This can also be interpreted as class A networks having a network mask of /8 or 255.0.0.0.
Similarly, the network bits in a class B address for medium networks was 16, leaving 16 bits for the host part. Class C networks had 24 bits reserved for the network and 8 for the hosts:
The following table summarizes the hosts and networks for the different classes of address:
The address structure discussed so far is generally referred to as classful addressing. This format of addressing had severe limitations as the IP networks expanded rapidly. Since the number of networks were finite, the demand for IP addresses far outnumbered what was available.
Also, the smallest networks had 254 addresses for hosts. However, even if there were 10 hosts on the network, the remaining addresses could not be used anywhere, the network numbers had to be unique, leading to a lot of wastage of the available IP addresses. This wastage of IP addresses became a big cause for concern and the industry started looking at new ways of reducing this wastage and finding efficient ways to use the available IP address space. This led to the introduction of classless addressing, where in the concept of bucketing all networks into small, medium, and large, and hence allocating class C, B, or A addresses was done away with.
In classless addressing, the number of network bits was not fixed like in classful addressing at 8, 16, or 24, but there was flexibility that the number of bits reserved for the network (Network mask) could be any number from 1 to 32. Hence, the networks could be partitioned into smaller networks called subnets, and the utilization of IP addresses improved drastically. This meant that any number of bits could be reserved for the host bits, and the remaining bits would be the network bits. Hence each network could have addresses that were as granular as the power of 2. For example, if the host bits were 4, there could be 24 addresses, similarly if the number of host bits were 5, there could be 25 addresses. Note that the usable addresses would still be 2 less than the actual number, one each being reserved for the network ID and the broadcast address.
As an example, consider a situation where there were four different LAN segments or networks that had 40 hosts each to be connected. If we had followed classful addressing, we would have assigned a class C address to each of the 4 LAN segments and utilized only 40 addresses out of the 254 available for use in each segment leading to a huge wastage of addresses. In classless addressing, the addressing is done based on the requirement of addresses.
In this example, since we need 40 addresses per network and we can allot addresses in powers of 2 (2, 4, 8, 16, 32, 64, 128, 256, and so on), the minimum number of addresses that would fulfil the requirement of 40 addresses is 64, which requires 6 bits for the hosts. Hence for one class C (/24) network, we can fulfil the requirement of four such networks. Let's assume that the address block 166.75.229.0/24 was allocated to us.
The same address block can be subnetted into four smaller subnets for each subnetwork. Since the address block allocated to us had a subnet mask of /24, the first 24 bits are fixed. Now we need 40 addresses per LAN segment and, as discussed earlier, we need 6 bits as the host bits for each subnetwork. The number of bits that we can use as the subnet bits are 32-24-6 or 2 bits. Using the 2 bits, we can have 22 or 4 subnets. This is shown in the following figure for the address block of 166.75.229.0/24. Note that the subnets now have a subnet mask of /26 or 255.255.255.192 because each subnet now has 26 bits that represent the subnet:
Note that in the new scheme of addressing, the subnet mask is not fixed at octet boundaries, but can have any value as long as it can be represented as a continuous string of binary1 followed by a continuous string of binary 0, and the total number of bits being 32. This concept of splitting subnets for creating smaller subnets, where each subnet can have different subnet masks depending upon the number of addresses required in the subnet is called Variable Length Subnet Masking (VLSM).
The concept of subnetting led to a large number of prefixes on the network. This led to an increase in the resources required for the routing tables that stored these prefixes. To overcome the effect of the increase in the number of prefixes, the standards defined a new concept called supernetting, which aggregated smaller prefixes into a fewer number of prefixes with a smaller netmask. We will discuss this later in the routing section.
This tutorial is an excerpt from "Implementing Cisco Networking Solutions" by Harpreet Singh and published by Packt. Use the code ORNCC10 at checkout to get the ebook for just $10 until May 31.