Somewhere along the line somehow someone seemed to try to take data out of the data center. The continued advance of Moore’s law shifted the focus from data to computing.
The tendency was to minimize the data being operated on and reduce the task to processing the absolute minimal subset of data needed to arrive at some actionable result; consequently, the value of the complete body of data available was lost.The focus was strictly on how fast some simple operation could operate on some small subset of data, over and over again in some fixed way.
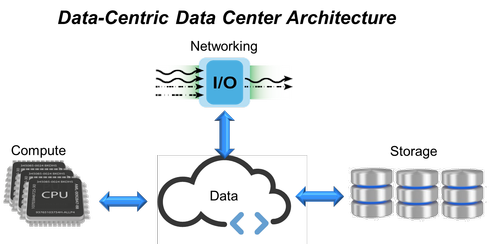
The largest cloud and Web 2.0 data centers are taking a different approach to capturing and analyzing all of the available data. This approach demands a shift from a compute-centric to a data-centric data center.
This data-centric data center architecture puts data back at the center of the data center, but perhaps even more interesting is that this enables server disaggregation, offering the flexibility to scale each element of the data center (compute, memory, I/O, and storage) independently and to optimize at the rack rather than server level. The key to this architecture is a focus on data and the requirement of a highly efficient network capable of ingesting, storing, moving and analyzing data throughout its useful lifecycle.
Data: Big, real-time, and unstructured
Instead of a focus on processing a very small chunk of data, the emphasis has shifted back to the data writ large -- all of it, everywhere, and all the time with more of it being generated every second. Real-time data is generated at a stunning rate from hundreds of millions of mobile devices and aggregated from millions of users to provide incredibly useful information tailored precisely for each individual user.
Google’s Waze mobile navigation application is a good example. Waze collects real-time GPS data from millions of mobile phones travelling silently along with their owners in a car. But silent only in the audible sense; they're actually screaming out massive quantities of real-time, location-based data, thereby providing incredibly valuable information on the travel patterns and speeds of millions of Waze subscribers.
All of this information is integrated for each individual user to provide unique information valuable to that user based on a combination of current location, destination, available roadways, and real-time traffic patterns. If you haven’t tried Waze yet, you must -- and marvel at the amount of pure data, as well as processing that is happening in real time in order to direct you to the traffic-free short cut you never knew existed.
The logical extension of Waze that minimizes an individual’s drive time is the self-driving car that will not only shorten trips, but eliminate traffic. Imagine travelling at 150+ kilometers per hour, while only a few meters away from the car in front of you. This will happen in our lifetimes and will be enabled by an incredible amount of data, and the movement and processing of that data. So the growth in data will not only continue to increase, but increase at an increasing rate.
Unfortunately, traditional data center architectures haven’t been built to deal with big, fast, unstructured data of this kind and magnitude. In the next installment of this three-part series, I'll explain how the new data-centric data center model makes this onslaught of data useful.