In the first post of this blog series on big data deployment models, I discussed some of the fundamental choices enterprises must make and shared a somewhat tongue-in-cheek flowchart to help people think about their options on how to host a new big data environment.
This time, I’d like to share some Enterprise Strategy Group research that shows the preferred infrastructure models for the leaders of upcoming big data, business intelligence, and analytics projects. Survey respondents were from midmarket to large enterprises in North America, representing a broad range of industries.
An easy observation is that no one approach is dominant. Yet this is also surprising, given the rhetoric from many vendors claiming to offer the ideal platform for big data. So this exercise to explore pros and cons of various models is worth pursuing further.
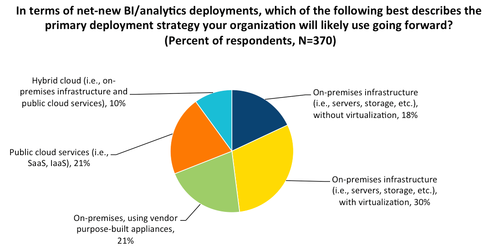
The diversity in the survey results highlights a couple of major criteria illustrated in the funny flowchart. Adding a few categories together, roughly 70% say they want to keep their analytics on-premises, compared to 20% opting for public cloud, and 10% combining some of both. Keeping big data in-house is most often done for reasons of cost, control, or compliance. Yet public cloud continues to grow as many don’t want to take on the burden of building out their own complex environments for unpredictable or temporary demands.
Note that the interest in and acceptance of cloud-based solutions varies quite widely by industry and by application, according to regulations and best practices, but also based on skill sets and management preferences. A decision on “where to host” will also have long-term implications as the volumes of data involved can make it much harder to relocate it all down the road. Further, market wisdom says that the analytics effort should be moved as close as possible to the data itself, so this affects not just storage, but future options for analytics applications.
Slicing the survey data another way, nearly 40% want either dedicated hardware components or pre-integrated appliances, as opposed to the 60% opting for some form of virtualized or shared infrastructure. The first camp generally cites a need for performance guarantees with a more tightly defined analytics workload. The latter group would suggest the higher utilization levels drives down costs and may also allow for more flexibility as needs change.
The market is starting to see more innovation around solutions to provide orchestration and administration for virtualization and even private clouds supporting big data clusters. Scale out may have some advantages over scale up, but sometimes at the cost of increased management complexity.
While the Hadoop ecosystem is still a relatively young approach, its momentum may be starting to skew the results, even if the data platform type isn’t clearly separated out in the chart above. Most people think of Hadoop as scale out on dedicated commodity server nodes, yet even here we are seeing more experimentation to fit the specific requirements of the application and environment. Both open source and commercial initiatives are allowing for more variety in the architecture.
What I find interesting is that the pattern of disruption of traditional data center IT practices by public, private, and hybrid cloud computing models is now repeating itself in the big data space. Perhaps the biggest difference is that ownership of big data initiatives increasingly originates outside the IT department. A data scientist or business analyst tends to think about analytics functionality, not enterprise operational requirements.
Stay tuned for my next blog post and more exploration of the various options in big data deployment models.