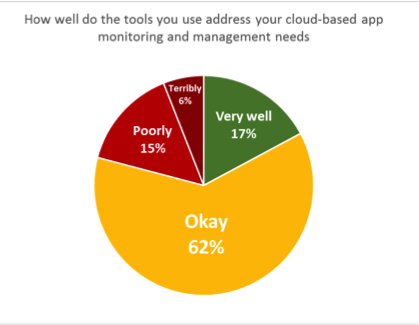
Recently, we conducted a study asking IT teams about their current and planned use of cloud apps and services within their organizations. One point really stood out: just 17% of respondents felt like their existing tools do a good job managing and monitoring their cloud-based apps. The rest were at best ambivalent about their existing tools, or felt that they weren't up to the task.
 Why? The systems management software market is mature, and includes sophisticated software and tools to manage everything from software distribution, to monitoring, to IT workflow and help desk activities. Why can't these products effectively manage cloud-based apps and services?
Why? The systems management software market is mature, and includes sophisticated software and tools to manage everything from software distribution, to monitoring, to IT workflow and help desk activities. Why can't these products effectively manage cloud-based apps and services?
There are a few reasons to consider.
Infrastructure ownership and access
Prior to the emergence of cloud computing, IT's management responsibilities didn't extend much beyond the walls of the enterprise, or for larger organizations, the periphery of their corporate area network. Traditional systems management tools were built and optimized with that in mind. Administrators had direct access to network, storage, and compute "boxes" that produced ample amounts of log files or SNMP messages. So their tools only needed to tap into those data feeds, send an alert when something happened, and maybe correlate logs from multiple systems so they could search for and identify trends.
But cloud has changed all that. If you run apps on Amazon Web Services or Azure, you can access app and OS logs, but below the OS you're blind. SaaS apps are completely black box: no log files, no SNMP messages, and most likely not even a management API to interface with. If your tools rely on these mechanisms, you're stuck.
Application management and network operations
It used to be that when users experienced a problem with an application, the IT team had tools to look for reported errors from the application or network. With traditional on-premise apps, the user device, access network, and application likely all reside on the same network, so between apps tools and infrastructure tools, IT could usually find and fix issues fairly quickly.
That's not the case with cloud-based apps. Now the application is a service that must be monitored and maintained. It's built on a complex web of networks, servers, and other services, most of which fall outside the organization's firewall. An admin now must have insight into the health of the application service as well as the networks and services (like ADFS) that are key to delivery of that application service. Neither the apps or ops group has a full view of the service delivery chain anymore; so they go back and forth pointing fingers and guessing haphazardly trying to find the root cause. We call this "chasing ghosts."
The agility mismatch
Traditional systems management solutions support a healthy industry of consultants and systems integrators with official certifications and ISO-9000 compliant project plans. It's not that these tools are poorly engineered; they simply evolved with the sophistication and complexity of enterprise applications and infrastructure management over the past decade.
 It's that same complexity explosion that is driving many organizations to the cloud. In fact, nearly 50% of respondents in our survey indicated that agility was a key driver for their move to the cloud.
It's that same complexity explosion that is driving many organizations to the cloud. In fact, nearly 50% of respondents in our survey indicated that agility was a key driver for their move to the cloud.
In the cloud, new apps and services come into the IT portfolio and are updated on a weekly basis. A management tool stack that requires a complex update every 12 months can't keep up.
Performance monitoring in a cloud era
The service delivery chain for cloud apps stretches across many service providers and local data centers and networks, with constant changes in access servers and routes. It's simply not feasible to have a tool that can find and access all the service nodes. So how can IT monitor cloud app performance?
In many cases, web pages or data protocol may be the only way to access these services, requiring synthetic testing of cloud-based apps and services. Looking at trends over time, admins can start to identify other anomalies and cyclical issues. As organizations move to the cloud, it will usher in a new era of IT management.







